Building a Serverless Audit Log Pipeline with AWS SAM — Easy, Fast & Fun

Introduction
When you’re running a distributed system, audit logs are your detective sidekick — they keep tabs on what’s happening, when, and by whom. But just having them isn’t enough; you need to capture and process them in a way that’s structured, reliable, and easy to query (because nobody wants to sift through a log swamp).
AWS gives us all the building blocks to make that happen. And with AWS SAM (Serverless Application Model), you can deploy the whole pipeline as clean, repeatable infrastructure-as-code — no clicking around consoles for hours.
In this post, we’ll walk through a serverless audit log ingestion pipeline. Our focus is on the integration side: setting up Firehose, adding a Lambda transformation to configure partition keys, and making sure the whole thing just works. We’ll touch on some ways to save money on S3 storage (because who doesn’t like that?), but cost optimization isn’t our main quest — that part depends heavily on your specific use case.
All code can be find here
Architecture Overview
Here’s the game plan for our audit log pipeline:
-
Client systems send their audit log JSONs via a humble HTTP POST to our API Gateway endpoint.
-
API Gateway calls the AuditReceiver Lambda function — basically the bouncer that checks IDs and lets the logs into the party.
-
The AuditReceiver Lambda hands the event over to a Kinesis Data Firehose delivery stream (think of it as a very fast conveyor belt).
-
Firehose summons the TransformationFunction Lambda, which gives the record a little makeover — enriching it and assigning partition keys based on the event’s metadata.
-
Finally, Firehose neatly stores the transformed events in S3, sorted into folders by audit type, year, month, and day, so future-you can find them without losing sanity.
Note: Yes, yes — having API Gateway trigger a Lambda here is not the most optimal setup. It’s just for demo purposes. In real life, you’d probably use something like an SNS topic or a Kinesis Data Stream for better scalability and lower latency.
Sam file overview
Since Firehose is the star of this blog, let’s zoom in on its configuration in our template.yaml (SAM file).
Firehose:
Type: AWS::KinesisFirehose::DeliveryStream
DependsOn:
- DeliveryStreamPolicy
Properties:
DeliveryStreamType: DirectPut
DeliveryStreamName: "kdf-firehose-audit-folgado"
ExtendedS3DestinationConfiguration: # where data is delivery
DynamicPartitioningConfiguration:
Enabled: true
BucketARN: !GetAtt DeliveryBucket.Arn
RoleARN: !GetAtt DeliveryStreamRole.Arn
ProcessingConfiguration: # will do transformations on the data
Enabled: true
Processors:
- Type: Lambda
Parameters:
- ParameterName: LambdaArn
ParameterValue: !GetAtt TransformationFunction.Arn # the lambda function that will process the data
BufferingHints:
IntervalInSeconds: 120
SizeInMBs: 64
CloudWatchLoggingOptions:
Enabled: true
LogGroupName: "/aws/kinesisfirehose/ibcd"
LogStreamName: "S3Delivery"
EncryptionConfiguration:
NoEncryptionConfig: "NoEncryption"
Prefix: "audit_type=!{partitionKeyFromLambda:audit_type}/year=!{partitionKeyFromLambda:year}/month=!{partitionKeyFromLambda:month}/day=!{partitionKeyFromLambda:day}/"
ErrorOutputPrefix: "errors/!{firehose:error-output-type}/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/"
A couple of key points
- Dynamic Partitioning To have Firehose automatically split your data into folders based on keys, you’ll need:
DynamicPartitioningConfiguration:
Enabled: true
-
Buffering size When using dynamic partitioning,
SizeInMBsmust be 64 MB or higher. No shortcuts here — Firehose insists on a healthy buffer. To not that if you go with Dynamic partition you your bufferringHing sizeInMDbs will must be equal or greater then 64 MBs. -
Prefix magic
Prefix: "audit_type=!{partitionKeyFromLambda:audit_type}/year=!{partitionKeyFromLambda:year}/month=!{partitionKeyFromLambda:month}/day=!{partitionKeyFromLambda:day}/"
ErrorOutputPrefix: "errors/!{firehose:error-output-type}/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/"
This is where the folder structure in S3 gets defined. In our case, we’re using a Lambda to set those partition keys — but if you don’t need transformations, Firehose can do this directly via inline paring.
How the Lambda decides partition keys
Inside our transformation Lambda, it’s as simple as:
transformedRecords = append(transformedRecords, events.KinesisFirehoseResponseRecord{
RecordID: record.RecordID,
Result: events.KinesisFirehoseTransformedStateOk,
Data: transformedData,
Metadata: events.KinesisFirehoseResponseRecordMetadata{
PartitionKeys: map[string]string{
"audit_type": event.EventType,
"year": year,
"month": month,
"day": day,
},
},
})
That’s it — the Lambda tags each record with its audit type, year, month, and day. Firehose then neatly drops them into matching folders in S3.
🎉 Result: beautiful, organized partitions that will make your future Athena queries much faster and easier to write.

Query audits
For our demo, we’ll keep things simple:
- AWS Glue Crawler will automatically scan our S3 bucket and build the data schema.
- AWS Athena will then let us query the logs with plain old SQL.
Now, a quick heads-up: Glue Crawlers are super convenient… but they can also rack up costs if you run them too often. In many cases, it’s cheaper (and faster) to create your own schema manually. That said, Crawlers are still magical when your data structure changes — they can automatically detect new formats and create new database schemas on the fly. Total hands-off mode.
As for Athena — it’s a great fit for occasional audit log digging. Perfect for:
- Tracking down that “mystery” API request
- Security investigations
- Spot checks on user activity
Since you only pay for what you query, it’s very budget-friendly for sporadic use.
Of course, Athena isn’t your only option. You could query your S3 data with engines like Trino or Redshift Spectrum (both using the Glue Data Catalog), and then connect analytics tools like Metabase on top. But for lightweight, serverless, and quick queries… Athena does the job without breaking a sweat.
Create Crawler and Run It
- Select your bucket where the audit logs are living their best life.
-
IAM Role time! The crawler needs permission to peek inside your bucket, so when AWS asks to create an IAM role, just nod and say yes.
-
Create your database and choose a crawler schedule. This determines how often Glue will check for new data and update your table schema (don’t set it to “every five seconds” unless you like surprise bills).
- Hit Create Crawler and then Run.
And… voilà! Your schema is now ready to be queried.
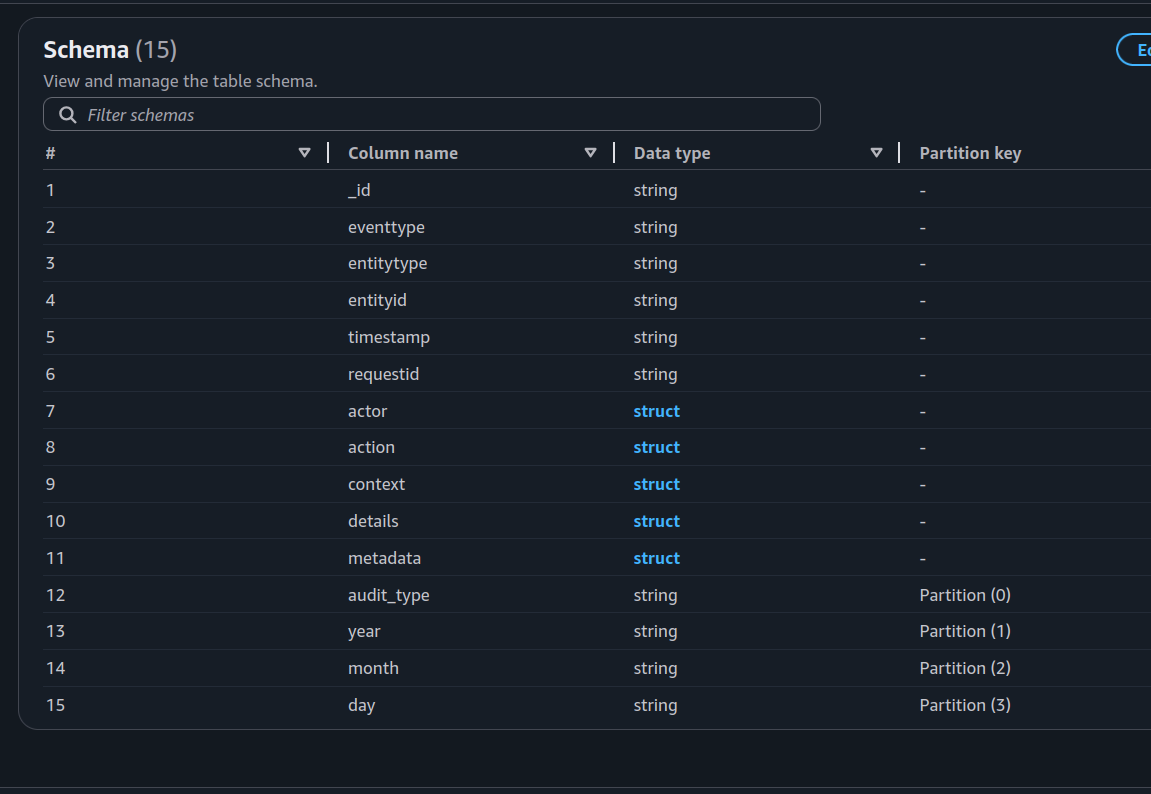
Query Data with Athenas
- Query all the data — just to see what’s there.
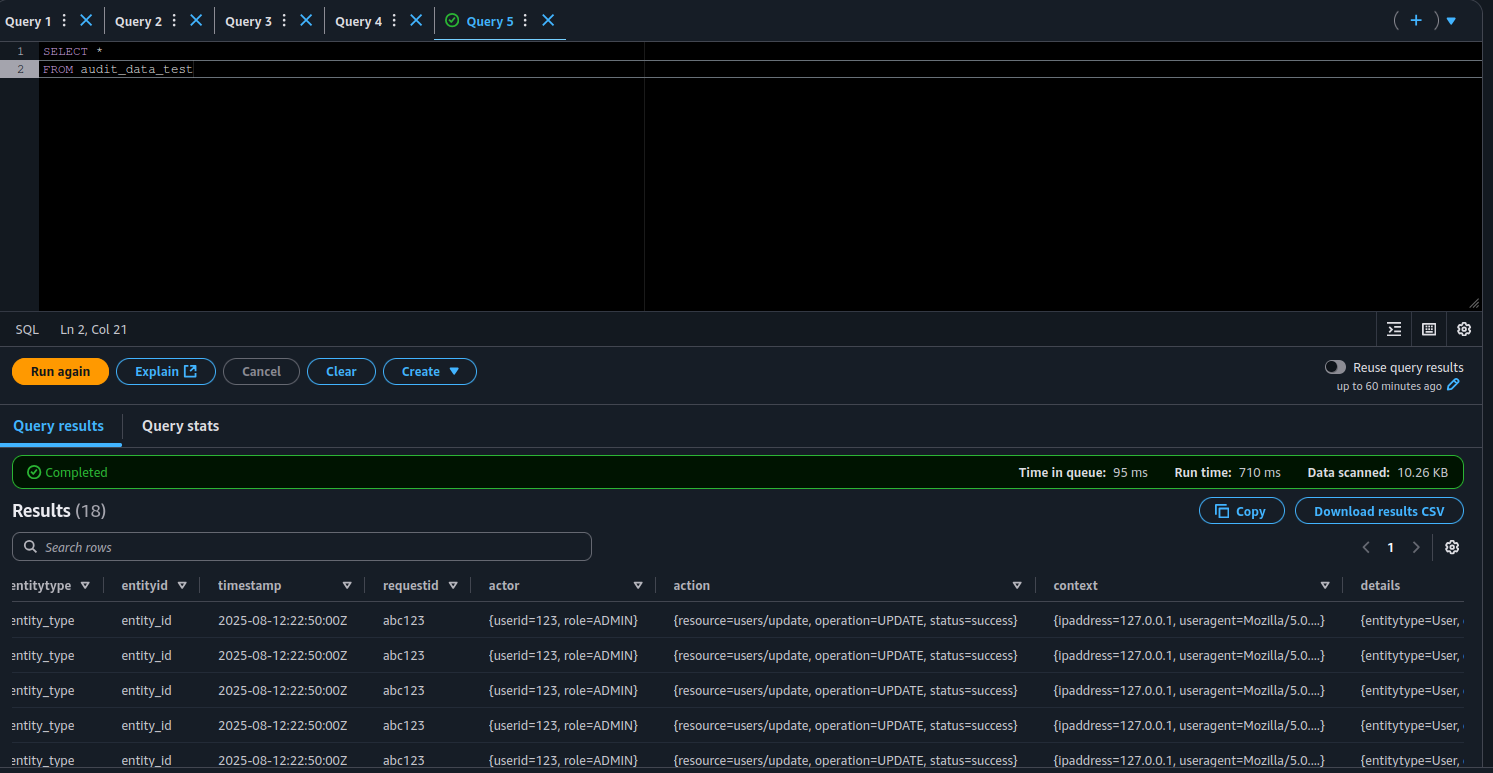
Notice the scanned data size? 10.26 KB.
- Now, let’s see the magic of partitions. Run a filtered query that uses your partition keys:
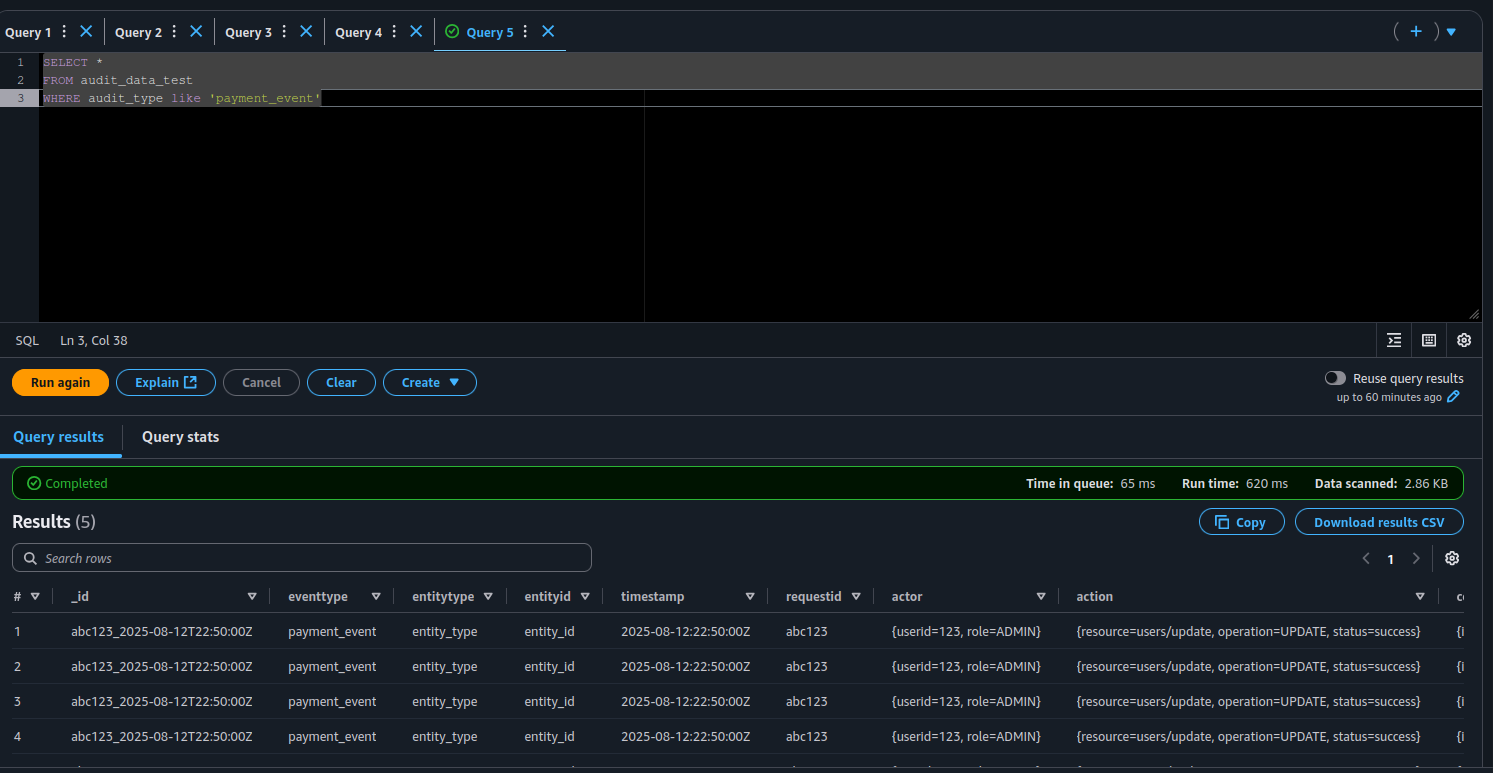
Boom — only 2.86 KB scanned. That’s the power of partitions: they work like indexes, so Athena doesn’t waste time (or your money) reading data you don’t need.

Cost Optimization Tips
This setup works great out of the box, but if you want to keep your AWS bill looking slim, here are a few tricks:
-
Compression is your friend — Use GZIP or Snappy to dramatically cut down S3 storage size. Smaller files = smaller bills.
-
Go columnar 📊 — Formats like Parquet or ORC not only compress well but also let Athena scan only the columns you need, which slashes query costs.
-
Bigger batches, fewer calls 📦 — Increase BufferingHints in Firehose so it processes larger batches, reducing how often Lambda gets called.
For most log analytics workloads, Parquet + Snappy is the sweet spot — compact storage and fast queries without losing flexibility.
And one more thing: archive your old data. If you only query the last 30 days, move the older stuff to S3 Glacier or Deep Archive. It’s like putting winter clothes in storage — you keep them just in case, but they’re not eating up prime closet space (or budget).
Conclusion
And that’s a wrap! You now have a neat, serverless audit log ingestion pipeline that’s easy to deploy with AWS SAM and keeps your logs organized for quick, cost-efficient querying.
We covered:
- Capturing audit logs with API Gateway and Lambda
- Setting up Firehose with dynamic partitioning and data transformation
- Using Glue Crawlers and Athena to make sense of your logs
- Ways to keep your AWS costs down without sacrificing performance
Oh, and one more thing worth thinking about: making your S3 audit files immutable — meaning once they’re saved, they can’t be changed or deleted. This helps keep your logs trustworthy and safe from tampering. AWS S3 Object Lock can help you with that.
With all this in place, you’ll be well-equipped to track and analyze your audit logs without too much hassle.
Happy logging! 🎉